简单记录一些深度学习相关知识。
机器学习与深度学习
通常要解决某个问题,特别是需要发现某种模式时,人们一般会综合考虑各种因素后再给出回答。人们以自己的经验和直觉为线索,通过反复试验推进工作。而机器学习的方法则极力避免人为介入,机器学习的方法中,由机器从收集到的数据中找出规律性。与从零开始想出算法相比,这种方法可以更高效地解决问题,也能减轻人的负担。但是需要注意的是,将图像转换为向量时使用的特征量仍是由人设计的。对于不同的问题,必须使用合适的特征量(必须设计专门的特征量),才能得到好的结果。
深度学习则比以往的机器学习方法更能避免人为介入,神经网络直接学习图像本身。利用特征量和机器学习的方法中,特征量仍是由人工设计的,而在神经网络中,连图像中包含的重要特征量也都是由机器来学习的。所以深度学习有时也称为端到端机器学习(endtoend machinelearning)。这里所说的端到端是指从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思。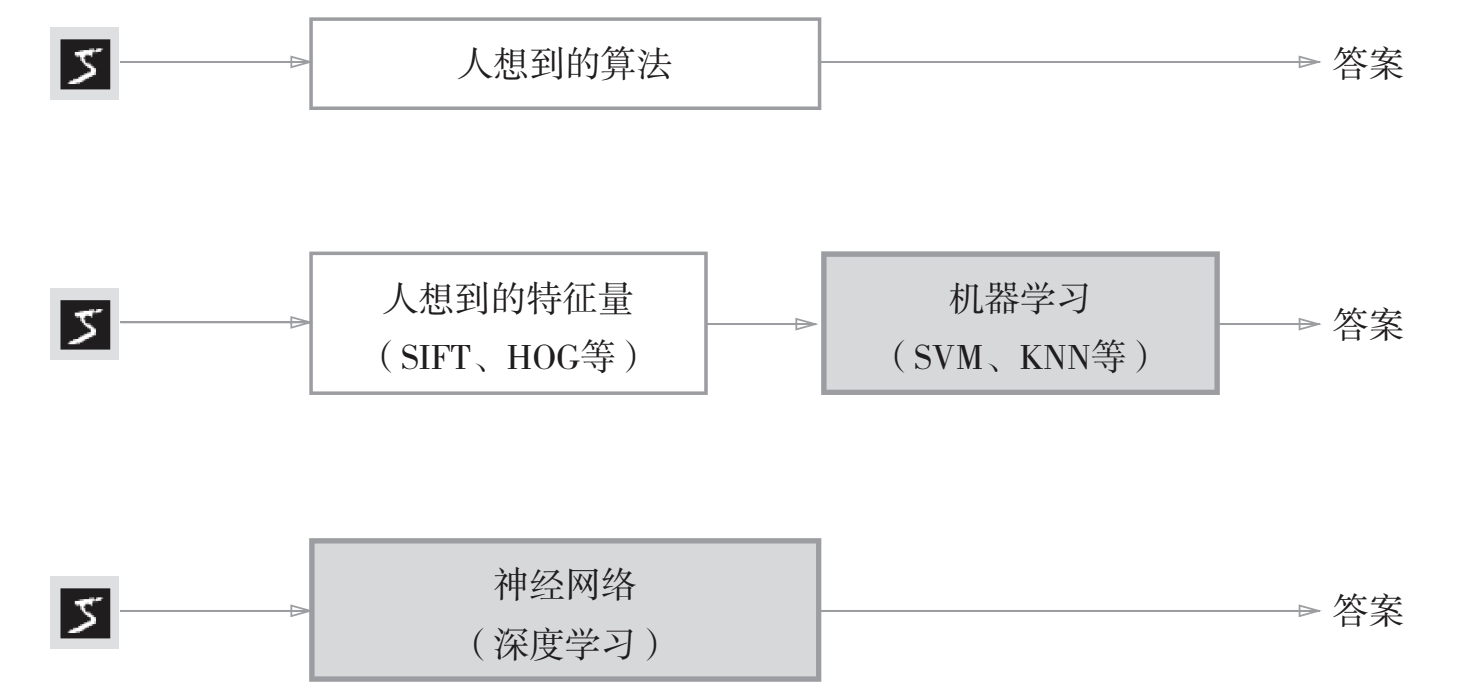
机器学习的最终目标是获得泛化能力(处理未被观察过的数据的能力)。在机器学习中,一般将数据分为训练数据(监督数据)和测试数据两部分来进行学习和实验等。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。
需要注意的是,只用一个数据集去学习和评价参数是无法进行正确评价的。这样会导致可以顺利地处理某个数据集,但无法处理其他数据集的情况(这种只对某个数据集过度拟合和的状态叫过拟合)。
接下来,会从深度学习基本概念开始,逐渐学习介绍。
感知机
接受多个输入信号,输出一个信号。信号只有“流/不流“(1/0)两种状态。下图即为接受两个输入信号的状态机。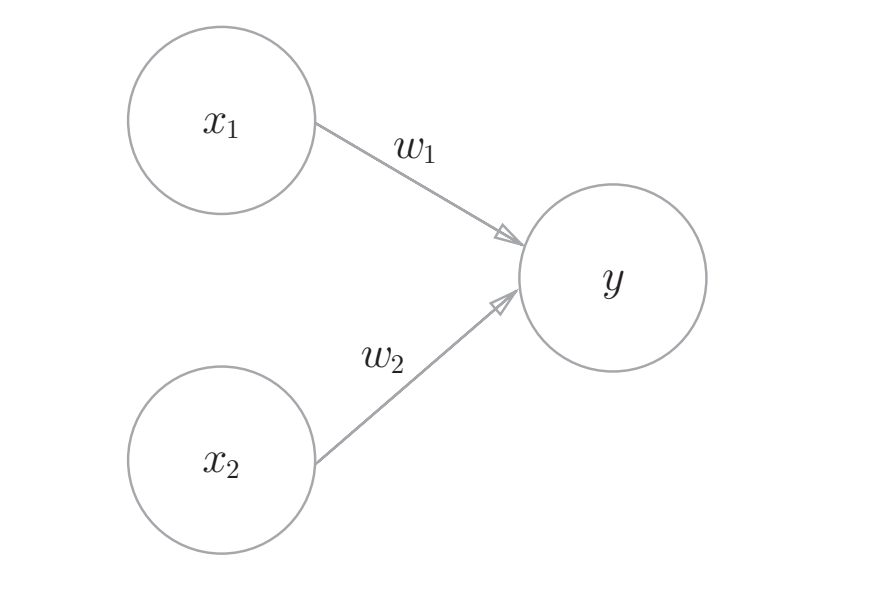
其中的$x_{1},x_{2}$分别为输入信号,$y$为输出信号,$w_{1},w_{2}$代表着权重。$\circ$被称为着“神经元”或者“节点”。输入信号被送往神经元时,会被分别乘以固定的权重即$(w_{1}x_{1},w_{2}x_{2})$。
神经元会计算传送过来的信号的总和,只有当这个总和超过了某个界限值时,才会输出$1$。这也称为”神经元被激活“。这里将这个界限值称为阈值,用符号$\theta$表示。用公式表示即:
每个输入信号都有各自的权重,权重越大,对应该权重的信号的重要性就越高。
将上式$\theta$换为$-b$还可写成另一种形式:
其中$b$被称为偏置,偏置是调整神经元被激活的容易程度的参数。
可以发现上图中偏置并没有直接表示,如需明确表示偏置$b$可以如下图: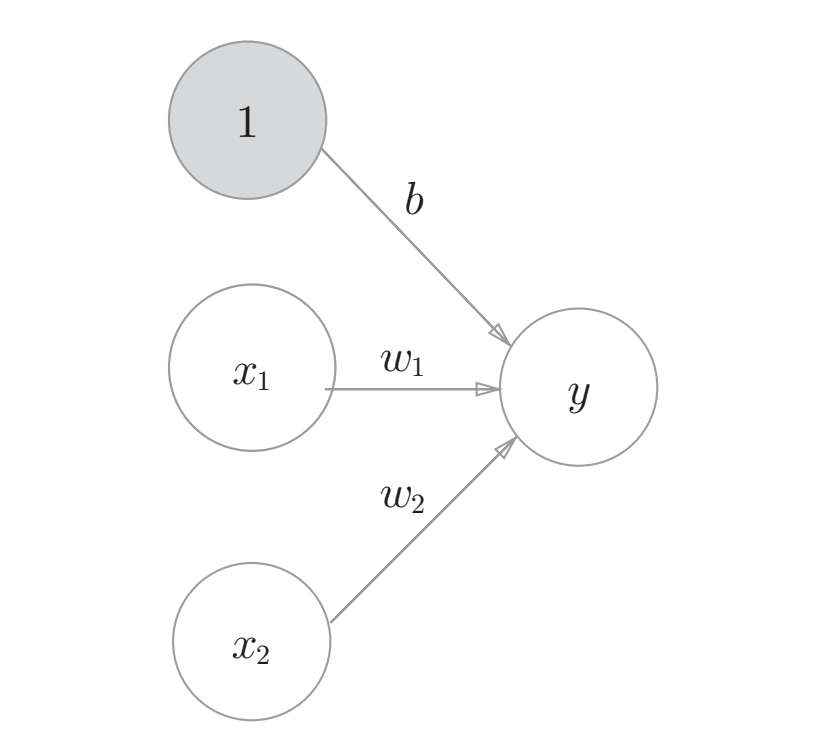
作用
可以在不改变感知机构造,仅通过改变感知机的参数,来实现与或非等逻辑电路。如:$(w_{1},w_{2},b)=(0.5,0.5,-0.7)$可以满足与门条件。而$(w_{1},w_{2},b)=(-0.5,-0.5,0.7)$可以表示与非门。(需要注意的是,对于同一个门电路,满足条件的参数选取有无数多个)
简单的与门实现:1
2
3
4
5
6
7
8def AND(x1, x2):
x = np.array([x1, x2])
w = np.array([w1, w2])
b = -0.7
tmp = b + np.sum(w * x)
if tmp <= 0:
return 0
return 1
局限性
感知机无法直接实现异或门,因为感知机只能表示由一条直线分割的空间,而无法分割如图所示的非线性空间(曲线分割而成的空间称为非线性空间,由直线分割而成的空间称为线性空间):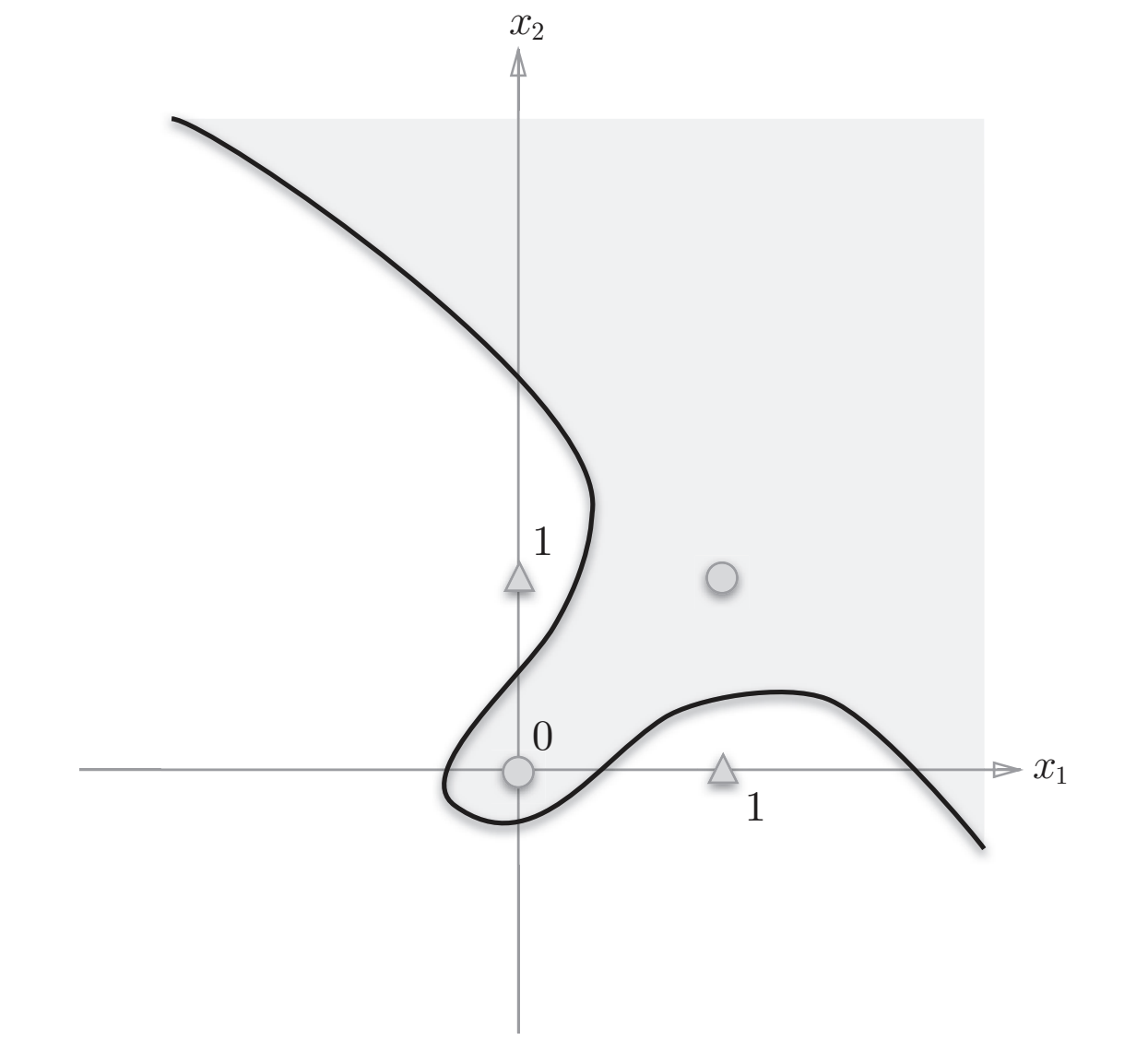
虽然感知机没办法直接实现,但是感知机可以进行叠加,进行非线性的表示,间接的实现复杂的逻辑电路。如:异或门可以通过组合与门、与非门、或门实现。这种叠加了多层的感知机也称为多层感知机。
激活函数
在感知机的公式中,我们可以用一个函数$h(x)$表示分情况的动作(超过0则输出1,否则输出0)。即可写作:
$h(x)$会将输入信号的总和转换为输出信号,这种函数一般称为激活函数(activation function),激活函数的作用在于决定如何来激活输入信号的总和。
用$a=b+w_{1}x_{1}+w_{2}x_{2}$来表示中间值,便可画出明确显示激活函数的计算过程: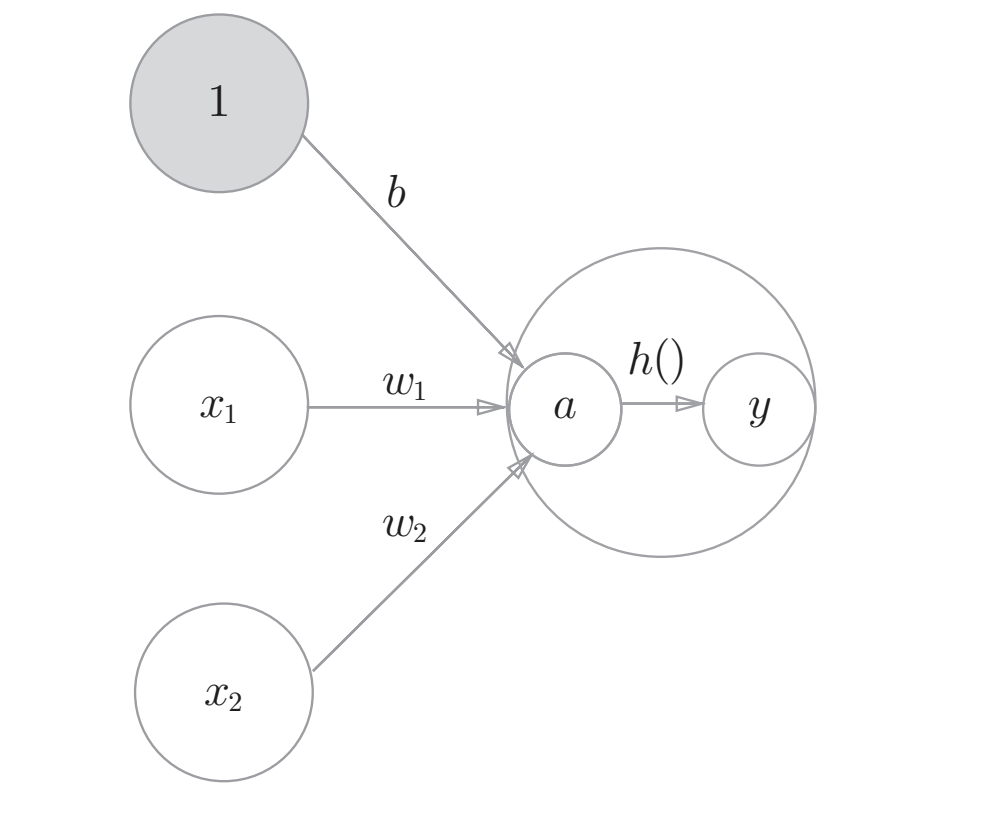
神经网络
即便对于复杂的函数,感知机也隐含着能够表示它的可能性。即便是计算机进行的复杂处理,感知机(理论上)也可以将其表示出来。但是设定权重的工作,即确定合适的、能符合预期的输入与输出的权重还是由人工进行的,为了可以自动地从数据中学习到合适的权重参数,需要用到神经网络。
神经网络图示如下图,最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层(也称为隐藏层)。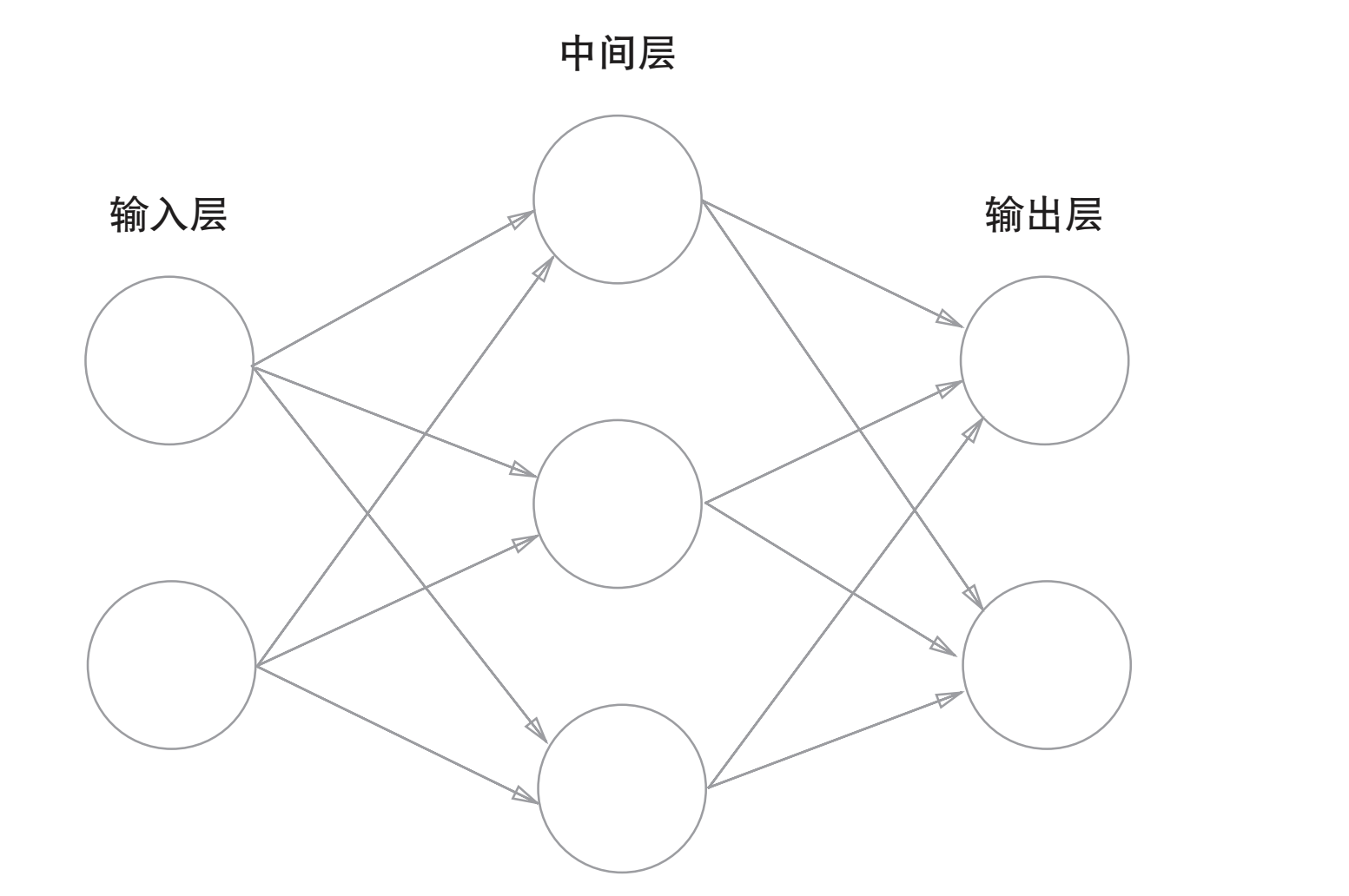
实际上,感知机和神经网络的主要区别就在于这个激活函数。在感知机中,常使用阶跃函数作为激活函数,而神经网络会选择其他的非线性函数作为激活函数,比如说sigmoid和Relu函数。
实现
首先是符号约定,上标表示权重和神经元的层号(即第1层的权重、第1层的神经元)。此外,权重的右下角有两个数字,它们是后一层的神经元和前一层的神经元的索引号。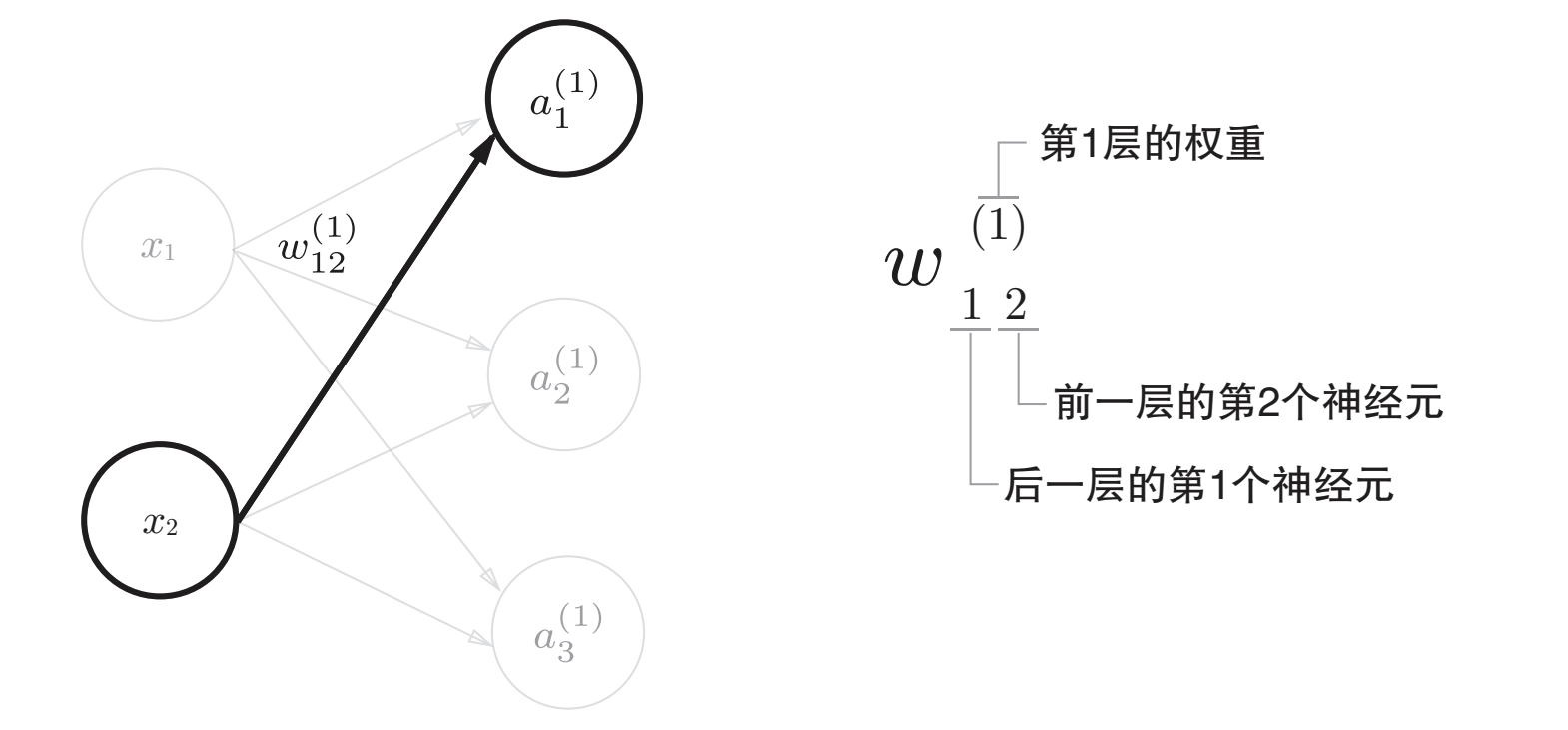
用数学式表示$a_{1}^{(1)}$,通过加权信号和偏置的和按如下方式进行计算:$a_{1}^{(1)}=w_{1 1}^{(1)}x_{1}+w_{12}^{(1)}+b_{1}^{(1)}$。显然,我们可以通过矩阵乘法的方式进行每一层的运算。令:
则有$\mathbf{A}^{(1)}=\mathbf{X}\mathbf{W}^{(1)}+\mathbf{B}^{(1)}$,此后$\mathbf{A}$会经由激活函数$h()$,转化为该层最终结果$\mathbf{Z}$。
用python实现:1
2
3
4
5X = np.array([x1, x2])
W1 = np.array([w11, w21, w31], [w12, w22, w32])
B1 = np.array([b1, b2, b3])
A1 = np.dot(X, W1) + B1
Z1 = h(A1)
输出层设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax函数。输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。
恒等函数
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直接输出。因此,在输出层使用恒等函数时,输入信号会原封不动地被输出。如下图: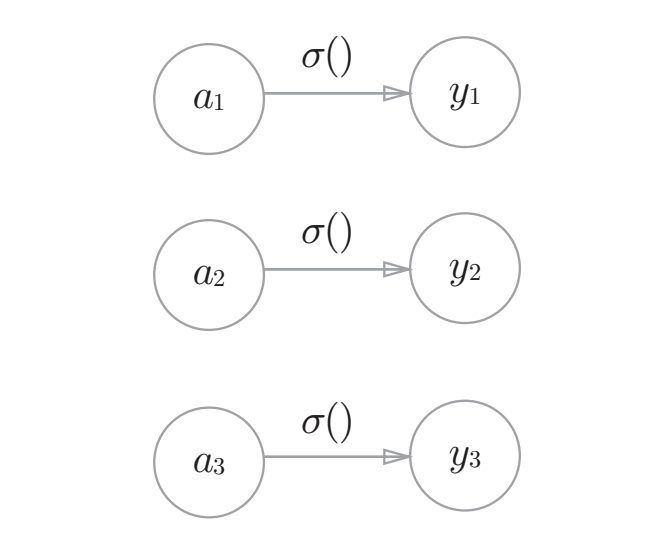
softmax函数
分类问题中假设输出层共有n个神经元,计算第$k$个神经元的输出$y_{k}$。第$k$个输入信号为$a_{k}$。
softmax函数为:$y_{k}=\frac{\exp(a_{k})}{\sum_{i=1}^{n}\exp(a_{i})}$。输出层的各个神经元都受到所有输入信号的影响。如图: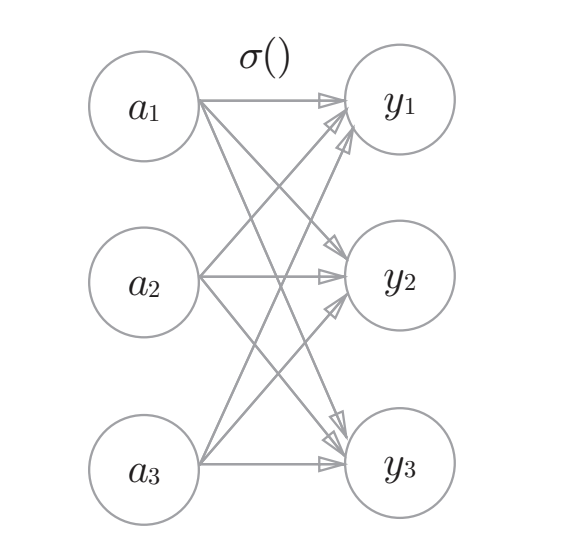
在计算机运算中,softmax函数的实现中要进行指数函数的运算,容易出现溢出。所以需要对式子进行变形:
可以看出,在进行softmax的指数函数的运算时,加上(或者减去)某个常数并不会改变运算的结果。所以一般会减去输入信号中的最大值以确保运算不会溢出。实现如下:1
2
3
4
5
6def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
softmax函数的输出是0到1之间的实数。并且,softmax函数的输出值的总和是1。正因如此,我们才可以把softmax函数的输出解释为“概率”。
这里需要注意的是,即便使用了softmax函数,各个元素之间的大小关系也不会改变。一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。使用softmax函数,输出值最大的神经元的位置并不会变,所以,在实际的问题中,由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数一般会被省略。
损失函数
神经网络的学习通过某个指标表示现在的状态,以这个指标为基准,寻找最优权重参数。神经网络的学习中所用的指标称为损失函数。(在进行神经网络的学习时,不能将识别精度作为指标。因为如果以识别精度为指标,则参数的导数在绝大多数地方都会变为0,因为稍微改变权重参数的值,精度并不会出现变化,精度不会产生连续变化,而是突然的变化。)损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
均方误差
假设$y_{k}$表示神经网络的输出,$t_{k}$表示监督数据,$k$表示数据的维数。均方误差如下式:
比如以softmax函数输出为举例:1
2
3
4y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
由于softmax函数的输出可以理解为概率,因此上例表示“0”的概率是0.1,“1”的概率是0.05,“2”的概率是0.6等。t是监督数据,将正确解标签设为1,其他均设为0。这里,标签“2”为1,表示正确解是“2”。将正确解标签表示为1,其他标签表示为0的表示方法称为one-hot表示。
均方误差越小,则说明与监督数据越符合。
交叉熵误差
$y_{k}$是神经网络的输出,$t_{k}$是正确解标签(one-hot表示),交叉熵误差如下式所示:
正确解标签对应的输出越大,式的值越接近0;当输出为1时,交叉熵误差为0。在实际实现中,一般会在计算$\log$时添加一个微小值$\delta$,以避免出现$\log_{e} 0$变为$-inf$而导致后续计算无法进行:1
2
3def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
mini-batch学习
机器学习使用训练数据进行学习。使用训练数据进行学习,严格来说,就是针对训练数据计算损失函数的值,找出使该值尽可能小的参数。因此,计算损失函数时必须将所有的训练数据作为对象。也就是说,如果训练数据有100个的话,我们就要把这100个损失函数的总和作为学习的指标(一般会除于样本总数,即进行正规化,以获得和训练数据的数量无关的统一指标)。
如交叉熵,假设数据有$N$个,$t_{nk}$表示第$n$个数据的第$k$个元素的值($y_{nk}$是神经网络的输出,$t_{nk}$是监督数据):
如果遇到大数据,数据量会有几百万、几千万之多,这种情况下以全部数据为对象计算损失函数是不现实的。因此,我们从全部数据中选出一部分,作为全部数据的“近似”。经网络的学习也是从训练数据中选出一批数据(称为mini-batch, 小批量),然后对每个mini-batch进行学习。